User Guide#
Before we go in depth into the implementation details of the different components of our Retrieval Augmented Generation (RAG) framework, we provide a high-level overview of the main components.
What is Retrieval Augmented Generation?#
Before to go in more details regarding Retrieval Augmented Generation (RAG), let’s first define the framework in which we will use a large language model (LLM). The graphic below represents the interaction between our user and the LLM.
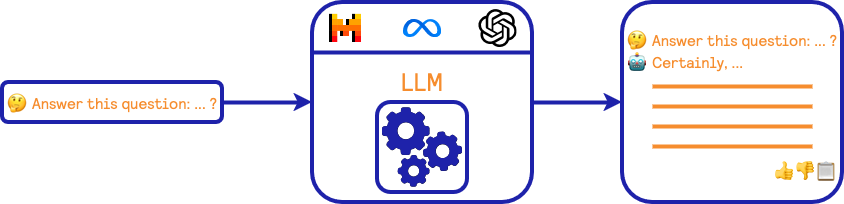
In this proof-of-concept (POC), we are interested in a “zero-shot” setting. It means that we expect our user to formulate a question in natural language, and the LLM will generate an answer.
The way to query the LLM can be done in two ways: (i) through an API such as when using GPT-* from OpenAI or (ii) by locally running the model using open-weight models such as Mistral or LLama.
Now, let’s introduce the RAG framework.
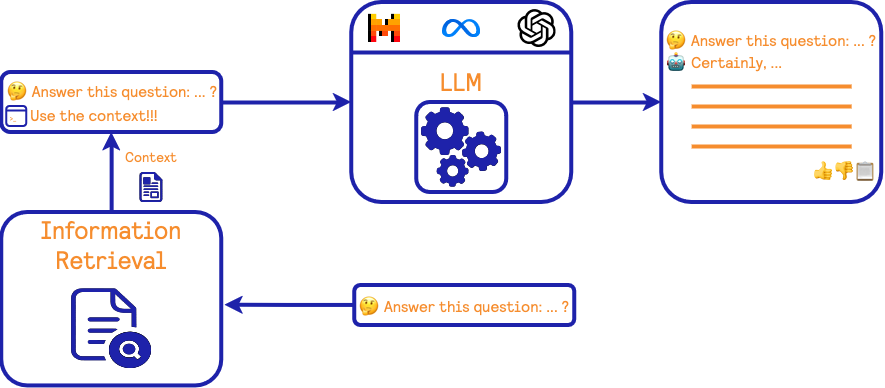
The major difference with the previous framework is an additional step that consists of retrieving relevant information from a given source of information before answering the user’s query. The retrieved information is provided as a context to the LLM during prompting, and the LLM will therefore generate an answer conditioned on this context.
It should be noted that information retrieval is not a new concept and has been extensively studied in the past. It is also related to the application of search engines. In the next section, we will go into more details about the information retrieval components when used for a RAG framework.
Information retrieval#
Concepts#
Before explaining how a retriever is trained, we will first show the main components of such a retriever.
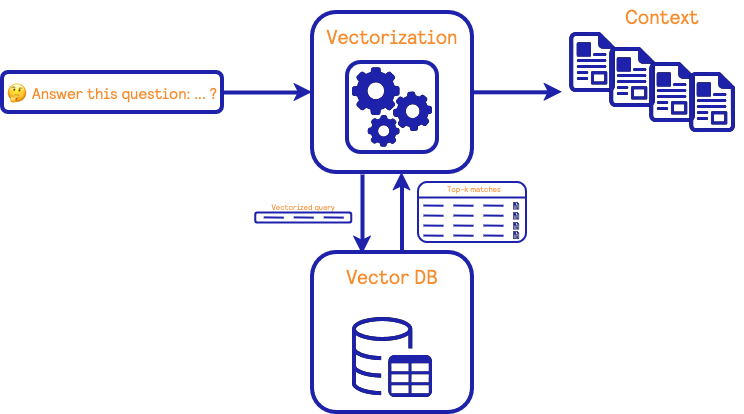
A retriever has two main components: (i) an algorithm to transform natural text into a mathematical vector representation and (ii) a database containing vectors and their corresponding natural text. This database is also capable of finding the most similar vectors to a given query vector.
During the training phase, a source of information containing natural text is used to build a set of vector representations. These vectors are used to populate the database.
During the retrieval phase, a user’s query is passed to the algorithm to create a vector representation. Then, the most similar vectors are found in the database, and the corresponding natural texts are returned. These documents are then used as context for the LLM in the RAG framework.
Details regarding the retrievers#
In this section, we will provide a couple of details regarding the retrievers. However, our reader can refer to the following comprehensive review for more details [1].
Without going into the details, we can distinguish two types of retrievers: (i) lexical retrievers based on the Bag-of-Words (BoW) model and (ii) semantic retrievers based on neural networks.
Lexical retrievers are based on word counts in documents and queries. They are simple but lack the ability to capture the meaning of words. Several approaches have been proposed to improve the performance of these retrievers by expanding queries, documents, or modeling topics. These retrievers create a sparse representation that can be leveraged to find the most similar documents through inverted indexes.
Semantic retrievers are based on neural networks and project the text into a continuous vector space. While they are better at capturing the meaning of words, they make the search more complex due to the dense representation. In this case, approximate nearest neighbors algorithms are used to find the most similar documents.
References#
Implementation details#
In the previous sections, we presented the general ideas behind the RAG framework. However, the devil is in the details. In the following sections, we will present some implementation details regarding some inner steps of the RAG framework that are important if you want to obtain meaningful results.