Retriever#
We differentiate two types of context retrievers: lexical and semantic.
Lexical retrievers#
Lexical retrievers are based on the bag-of-words approach. The idea is to count the term frequency in documents and queries and based on a score, rank the documents. We could think that with this approach, documents with similar words distribution are likely to be similar.
However, we can also infer a limitation: since this is based on term frequency, the retriever does not take into account the meaning of the words. For instance, this is not robust to synonyms or to the context of the words.
Here, we implement the BM25Retriever that uses a
CountVectorizer to build the
vocabulary. Then, we use a TF-IDF weighting scheme to weight the vocabulary.
During the a query, we provide a similarity score between the query and the
each documentation chunk seen during training. We can represent the retriever with the
following diagram:
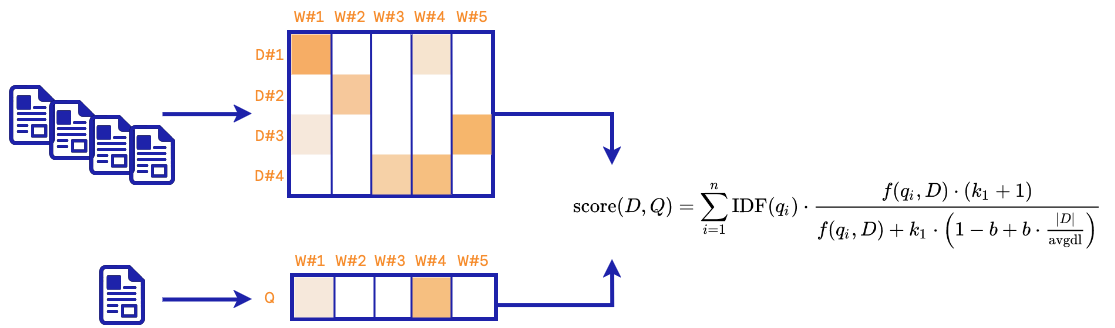
To have more details regarding the scoring used by the BM25 retriever, you can refer to this Wikipedia page.
Semantic retrievers#
In semantic retrievers, the idea is to have a more flexible match between the query and the documentation. We use an embedding model to project a document into a vector space. During the training, these vectors are used to build a vector database. During the query, we project the query into the vector space and we retrieve the closest documents. The semantic retrievers are more likely to make sense of words positioning and words similarity.
SemanticRetriever are using a given embedding and an
approximate nearest neighbor algorithm, namely FAISS.
As embedding, we provide a SentenceTransformer that
download any pre-trained sentence transformers from HuggingFace. A diagram representing
this approach is:
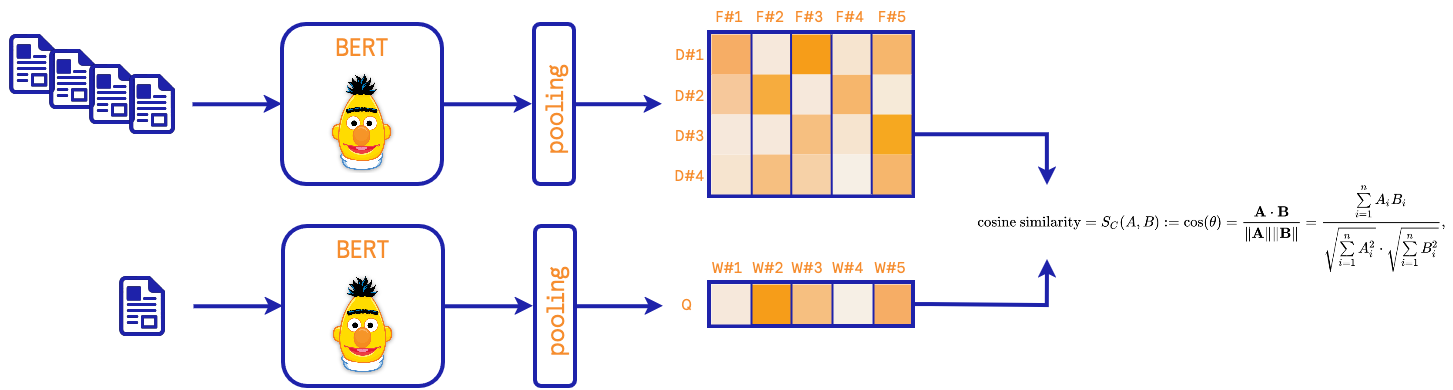
Reranker: merging lexical and semantic retrievers results#
If we use both lexical and semantic retrievers, we need to merge the results of both
retrievers. RetrieverReranker makes such reranking by
using a cross-encoder model. In our case, cross-encoder model is trained on Microsoft
Bing query-document pairs and is available on HuggingFace. A diagram showing the
reranking process is:
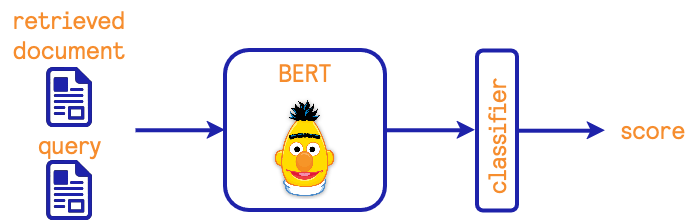
API of retrivers and reranker#
All retrievers and reranker adhere to the same API with a fit and query method.
For the retrievers, the fit method is used to create the index while the query
method is used to retrieve the top-k documents given a query.