Note
Go to the end to download the full example code.
Enhancing cross-validation#
This example illustrates the motivation and the use of skore’s
skore.cross_validate() to get assistance when developing your
ML/DS projects.
Creating and loading the skore project#
We start by creating a temporary directory to store our project such that we can easily clean it after executing this example. If you want to keep the project, you have to skip this section.
import tempfile
from pathlib import Path
temp_dir = tempfile.TemporaryDirectory(prefix="skore_example_")
temp_dir_path = Path(temp_dir.name)
import subprocess
# create the skore project
subprocess.run(
f"python3 -m skore create my_project_cv --working-dir {temp_dir.name}".split()
)
CompletedProcess(args=['python3', '-m', 'skore', 'create', 'my_project_cv', '--working-dir', '/tmp/skore_example_jun1ca6_'], returncode=0)
import skore
my_project_gs = skore.load(temp_dir_path / "my_project_cv.skore")
Cross-validation in scikit-learn#
Scikit-learn holds two functions for cross-validation:
Essentially, sklearn.model_selection.cross_val_score() runs cross-validation for
single metric evaluation, while sklearn.model_selection.cross_validate() runs
cross-validation with multiple metrics and can also return extra information such as
train scores, fit times, and score times.
Hence, in skore, we are more interested in the
sklearn.model_selection.cross_validate() function as it allows to do
more than the historical sklearn.model_selection.cross_val_score().
Let us illustrate cross-validation on a multi-class classification task.
Single metric evaluation using sklearn.model_selection.cross_validate():
from sklearn.model_selection import cross_validate as sklearn_cross_validate
cv_results = sklearn_cross_validate(clf, X, y, cv=5)
print(f"test_score: {cv_results['test_score']}")
test_score: [0.96666667 1. 0.96666667 0.96666667 1. ]
Multiple metric evaluation using sklearn.model_selection.cross_validate():
import pandas as pd
cv_results = sklearn_cross_validate(
clf,
X,
y,
cv=5,
scoring=["accuracy", "precision_macro"],
)
test_scores = pd.DataFrame(cv_results)[["test_accuracy", "test_precision_macro"]]
test_scores
In scikit-learn, why do we recommend using cross_validate over cross_val_score?#
Here, for the SVC, the default score is the accuracy.
If the users want other scores to better understand their model such as the
precision and the recall, they can specify it which is very convenient.
Otherwise, they would have to run several
sklearn.model_selection.cross_val_score() with different scoring
parameters each time, which leads to more unnecessary compute.
Why do we recommend using skore’s cross_validate over scikit-learn’s?#
In the example above, what if the users ran scikit-learn’s
sklearn.model_selection.cross_validate() but forgot to manually add a
crucial score for their use case such as the recall?
They would have to re-run the whole cross-validation experiment by adding this
crucial score, which leads to more compute.
Cross-validation in skore#
In order to assist its users when programming, skore has implemented a
skore.cross_validate() function that wraps scikit-learn’s
sklearn.model_selection.cross_validate(), to provide more
context and facilitate the analysis.
Classification task#
Let us continue with the same use case.
cv_results = skore.cross_validate(clf, X, y, cv=5, project=my_project_gs)
fig_plotly_clf = my_project_gs.get_item("cross_validation").plot
fig_plotly_clf
Note
Because Plotly graphs currently do not properly render in our Sphinx auto-examples docs engine due to a bug in Plotly, we also display its static image below. Alternatively, we recommend zooming in / out in your browser window for the Plotly graphs to display properly.
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
fig_plotly_clf.write_image("plot_03_cross_validate_clf.png", scale=4)
img = mpimg.imread("plot_03_cross_validate_clf.png")
fig, ax = plt.subplots(layout="constrained", dpi=200)
ax.axis("off")
ax.imshow(img)
plt.show()
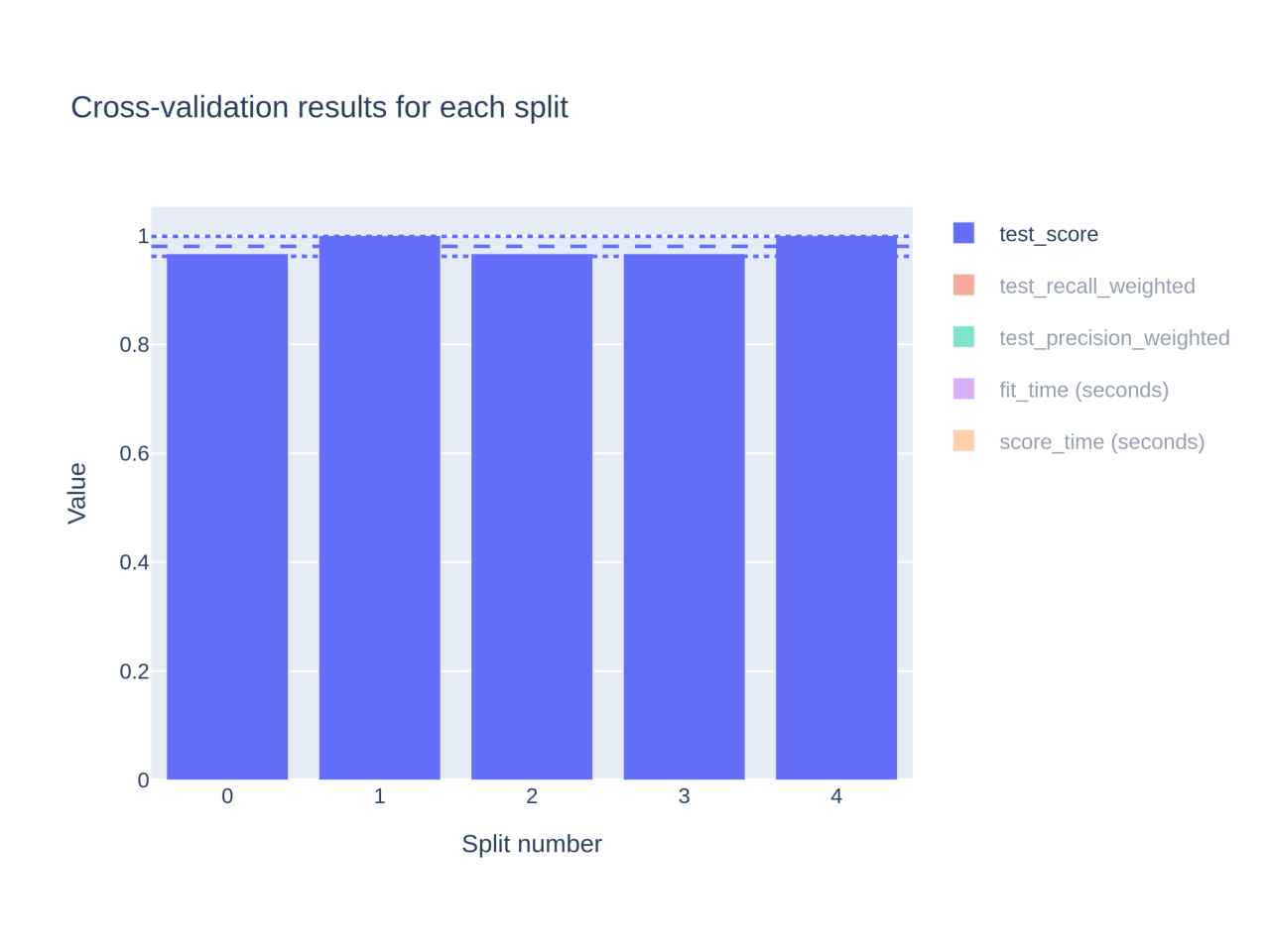
Skore’s cross_validate() advantages are the following:
By default, it computes several useful scores without the need for the user to manually specify them. For classification, you can observe that it computed the accuracy, the precision, and the recall.
You automatically get some interactive Plotly graphs to better understand how your model behaves depending on the split. For example:
You can compare the fitting and scoring times together for each split.
You can compare the accuracy, precision, and recall scores together for each split.
The results and plots are automatically saved in your skore project, so that you can visualize them later in the UI for example.
Regression task#
For now, all cross-validation runs store their results in the same place, which might lead to comparing two different models that are actually not comparable (e.g. comparing a regression with a classification). To remedy this, we clear the cross-validation information stored in skore before running another unrelated cross-validation:
my_project_gs.delete_item("cross_validation")
my_project_gs.delete_item("cross_validation_aggregated")
Note
Soon, the storage of several unrelated cross-validation runs will be managed automatically.
from sklearn.datasets import load_diabetes
from sklearn.linear_model import Lasso
diabetes = load_diabetes()
X = diabetes.data[:150]
y = diabetes.target[:150]
lasso = Lasso()
cv_results = skore.cross_validate(lasso, X, y, cv=5, project=my_project_gs)
fig_plotly_reg = my_project_gs.get_item("cross_validation").plot
fig_plotly_reg
Cleanup the project#
Remove the temporary directory:
temp_dir.cleanup()
Total running time of the script: (0 minutes 1.635 seconds)