Choosing a classification metric#
This notebook illustrates the impact of transforming predicted probabilities on the different metrics used to evaluate classification models. Based on those experiment we derive recommendations of the choice of classification metrics.
Ranking metrics are not impacted by monotonic transformations#
In this exercise, we empirically check that ranking metrics are not impacted by monotonic transformations. We will use the ROC-AUC score as an example.
Exercise:#
Write a function that maps values from [0, 1] to [0, 1] in a monotonically increasing way:
import numpy as np
import matplotlib.pyplot as plt
def monotonic_function(x):
# TODO: change me to something non-trivial but still monotonic.
return x
x = np.linspace(0, 1, 1000)
y = monotonic_function(x)
_ = plt.plot(x, y)
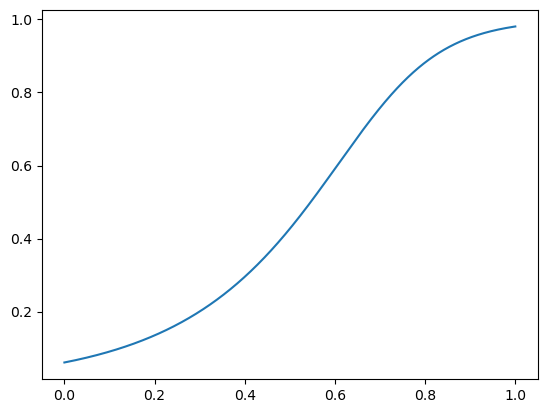
Solution:#
from scipy.special import expit
def monotonic_function(x):
return expit((x - 0.7) * 10) ** 0.4
# Or alternatively, a simple power transformation:
# return x ** 2
# return x ** 0.3
x = np.linspace(0, 1, 1000)
y = monotonic_function(x)
_ = plt.plot(x, y)
from sklearn.metrics import roc_auc_score
y_observed = np.asarray([1, 0, 1, 1, 0])
y_predicted_probs = np.asarray([0.1, 0.9, 0.3, 0.5, 0.2])
def compare_metrics(metric_func, transformation_func, y_observed, y_predicted_probs):
metric_name = metric_func.__name__
a = metric_func(y_observed, y_predicted_probs)
b = metric_func(y_observed, transformation_func(y_predicted_probs))
print(f"{metric_name} on original soft predictions: {a:.4f}")
print(f"{metric_name} on transformed soft predictions: {b:.4f}")
compare_metrics(roc_auc_score, monotonic_function, y_observed, y_predicted_probs)
roc_auc_score on original soft predictions: 0.3333
roc_auc_score on transformed soft predictions: 0.3333
Exercise:#
Check that the same result holds for other ranking metrics such as
average_precision_score.Tweak the values in
y_predicted_probsto see that this property holds in general.
from sklearn.metrics import average_precision_score
# TODO: tweak me!
y_predicted_probs = np.asarray([0.1, 0.9, 0.3, 0.5, 0.2])
# TODO: write me!
Solution:#
from sklearn.metrics import average_precision_score
compare_metrics(
average_precision_score, monotonic_function, y_observed, y_predicted_probs
)
average_precision_score on original soft predictions: 0.5889
average_precision_score on transformed soft predictions: 0.5889
y_predicted_probs = np.asarray([0.4, 0.9, 0.3, 0.5, 0.0])
compare_metrics(roc_auc_score, monotonic_function, y_observed, y_predicted_probs)
compare_metrics(
average_precision_score, monotonic_function, y_observed, y_predicted_probs
)
roc_auc_score on original soft predictions: 0.5000
roc_auc_score on transformed soft predictions: 0.5000
average_precision_score on original soft predictions: 0.6389
average_precision_score on transformed soft predictions: 0.6389
Proper scoring rules are impacted by monotonic transformations#
Exercise:#
Check that
neg_log_lossandbrier_score_lossare impacted by monotonic transformations.
# TODO: write me!
Solution:#
from sklearn.metrics import log_loss, brier_score_loss
compare_metrics(log_loss, monotonic_function, y_observed, y_predicted_probs)
log_loss on original soft predictions: 1.0232
log_loss on transformed soft predictions: 1.3492
compare_metrics(brier_score_loss, monotonic_function, y_observed, y_predicted_probs)
brier_score_loss on original soft predictions: 0.3820
brier_score_loss on transformed soft predictions: 0.4742
There is no particular reason to expect that our choice of transformation would improve calibration on this dataset. Ranking is unchanged (as measured by ROC-AUC). As a result, the proper scoring losses are degraded.
Hard classification metrics only depends on the value of the threshold#
Question:#
Under which conditions are thresholded / hard classification metrics such as (accuracy, precision, recall, F1 score, …) impacted by monotonic transformations of the predicted probabilities?
# TODO: write me!
Solution:#
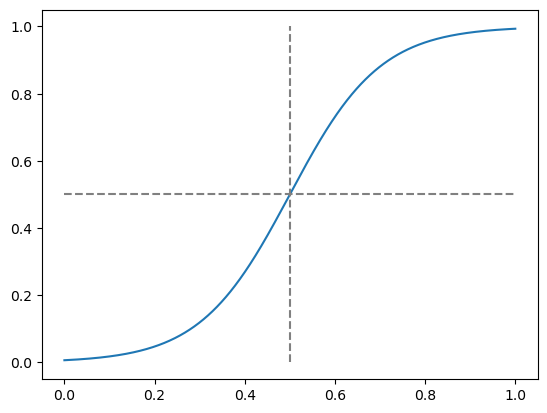
Thresholded metrics are not impacted by monotonic transformations if the threshold is left unchanged at 0.5 after the transformation.
def threshold_preserving_transformation(x):
return expit((x - 0.5) * 10)
x = np.linspace(0, 1, 1000)
y = threshold_preserving_transformation(x)
plt.plot(x, y)
plt.hlines(0.5, 0, 1, colors="gray", linestyles="--")
_ = plt.vlines(0.5, 0, 1, colors="gray", linestyles="--")
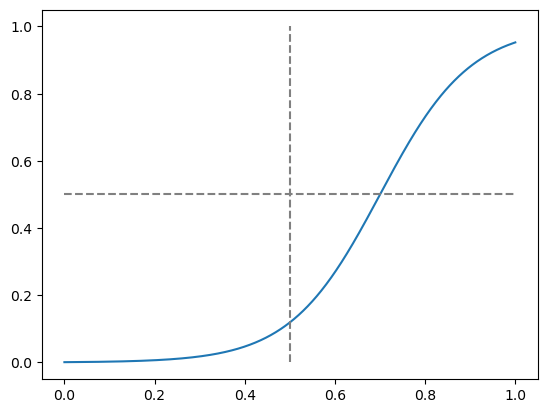
def non_threshold_preserving_transformation(x):
return expit((x - 0.7) * 10)
y = non_threshold_preserving_transformation(x)
_ = plt.plot(x, y)
_ = plt.hlines(0.5, 0, 1, colors="gray", linestyles="--")
_ = plt.vlines(0.5, 0, 1, colors="gray", linestyles="--")
from sklearn.metrics import f1_score
y_observed = np.asarray([1, 0, 1, 1, 0])
y_predicted_probs = np.asarray([0.6, 0.9, 0.3, 0.7, 0.2])
f1_score(y_observed, y_predicted_probs >= 0.5)
0.6666666666666666
f1_score(y_observed, threshold_preserving_transformation(y_predicted_probs) > 0.5)
0.6666666666666666
f1_score(y_observed, non_threshold_preserving_transformation(y_predicted_probs) > 0.5)
0.0
Summary:#
Ranking metrics are not impacted by monotonic transformations.
Proper scoring rules are impacted by monotonic transformations: a strictly increasing transformation changes the calibration term of the proper scoring loss while preserving the grouping loss (ranking) and the irreducible error (independent of the model predictions).
Hard classification metrics can be impacted by a monotonic transformation \(t\) of the soft predictions if \(t(0.5) \neq 0.5\) (assuming the default 0.5 decisin threshold).
As a consequence:
Using a hard classification metric to evaluate a probabilitic classifier does not inform us at all about the ability of the model to yield correct soft predictions. Hard classification metrics can be very sensitive to the choice of the threshold. As a result, they are only meaningful if we also tune the threshold according to a specific choice of hard classification metric that should ideally reflect the business objective.
Using a ranking loss to evaluate a probabilistic classifier only partially informs us about the ability of the model to yield correct soft predictions.
Proper scoring rules jointly evaluate both calibration and resolution (ranking power). They are the only metrics that are guaranteed to identify the best probabilistic model.